Hey Guys, today I’m going to create an article on PIVOT TABLE in Python with the help of Pandas. So, Pivot Table is basically tabled summarize data, they can be used to find unique values in a field. This is a good way to quickly see all the values that appear in a field and also find typos and other inconsistencies.
We perform reading CSV File and convert into a Pivot table.
Sample Data which help us to create the Pivot Table.
Table of Contents
Import Pandas module for reading CSV file
import pandas as pd
Read the CSV file using Pandas
data = pd.read_csv(r"C:\Users\Jamaley\Videos\sample_csv.csv")
[supsystic-tables id=1]
Data is a data frame variable which holds the CSV file.
Class Div Score Ramesh 1st 4 Ramesh 1st 24 Abhishek 2nd 31 Jamaley 2nd 2 Jamaley 1st 3 Rahul 1st 4 Raja 2nd 24 Rahul 2nd 31 Raja 1st 2 Nilesh 1st 3 Jamaley 2nd 2 Abhishek 2nd 3
Create a pivot table
pd.pivot_table(data, index=['Class','Div'])
Create a spreadsheet-style pivot table as a DataFrame. The levels in the pivot table will be stored in MultiIndex objects (hierarchical indexes) on the index and columns of the result DataFrame.
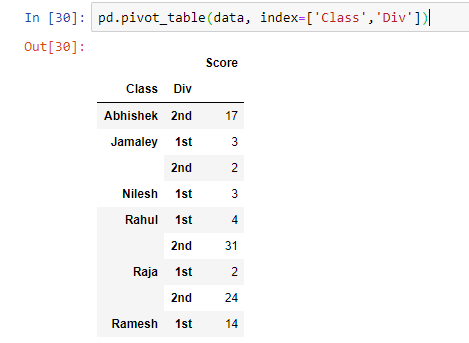
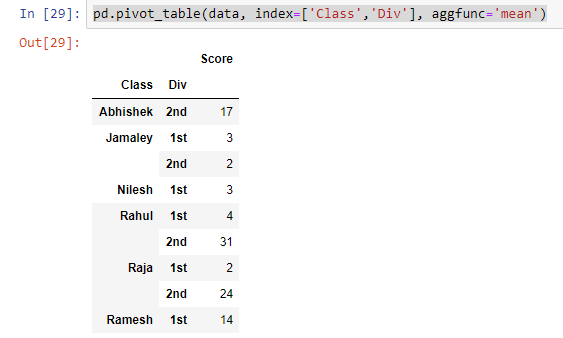
Create a pivot table (Mean)
pd.pivot_table(data, index=['Class','Div'], aggfunc='mean')
taking the mean across columns
Create a pivot table (count)
pd.pivot_table(data, index=['Class','Div'], aggfunc='count')
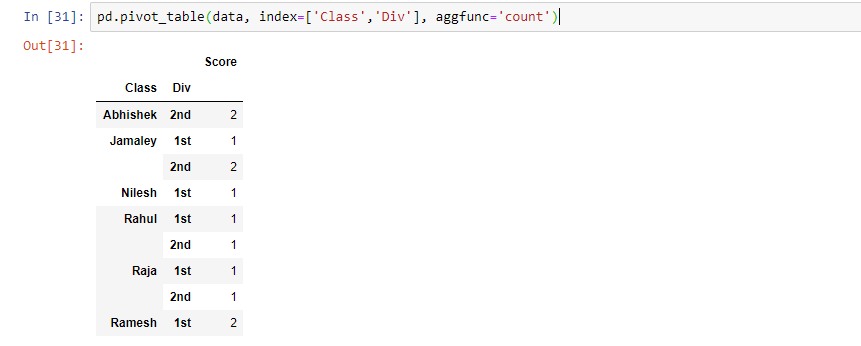
Note Table Headers for CSV are as follow – Class, Div, Score.
Check Similar articles.
Data Science – First Step with Python and Pandas (Read CSV File)
hope this post helped you to know Creating Pivot Table with Pandas. To get the latest news and updates follow us on twitter & facebook, subscribe to our YouTube channel. And If you have any query then please let us know by using the comment form.



Hey Great Content, thanks for publishing